
RAG Explained: How AI Retrieves Information Before Answering
Artificial Intelligence has evolved significantly over the past few years. Modern AI systems are no longer limited to generating responses solely from information learned during training. Organizations today expect AI applications to provide accurate, context-aware, and up-to-date answers while working with large volumes of business data. This growing demand has led to the adoption of Retrieval Augmented Generation, commonly known as RAG.
As Generative AI continues transforming industries, professionals involved in software development, cloud computing, data engineering, and machine learning increasingly encounter RAG-based systems. Understanding how these systems work is becoming an important part of technical learning and professional development.
Unlike traditional Large Language Models that rely entirely on their training data, RAG introduces a retrieval mechanism that allows the model to access relevant information before generating a response. This significantly improves accuracy, reduces hallucinations, and enables AI applications to work with continuously updated information sources.
What Is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation is an AI architecture that combines information retrieval with language generation.
Instead of directly answering a user's query, the system first searches a knowledge source for relevant information. The retrieved content is then provided to the language model, which uses that context to generate a more informed response.
This approach allows AI systems to work with:
- Enterprise documentation
- Product manuals
- Research papers
- Internal knowledge bases
- Customer support records
- Technical documentation
- Organizational databases
By accessing relevant information at runtime, RAG systems can deliver responses that are grounded in actual data rather than relying entirely on memory from training.
Why Do Traditional AI Models Struggle with Information Accuracy?
Large Language Models are trained on enormous datasets containing books, websites, articles, and other publicly available content. While this enables them to understand language patterns exceptionally well, they still face several limitations.
Knowledge Cutoff Limitations
Training data is collected at a specific point in time. Any information published after that period is unavailable to the model.
As a result, traditional models may not know:
- Recent company updates
- Newly released technologies
- Latest regulations
- Current market trends
- Updated technical documentation
Hallucination Problems
One of the most widely discussed challenges in Generative AI is hallucination.
A hallucination occurs when the model confidently generates information that appears correct but is actually inaccurate or completely fabricated.
This happens because the model predicts likely text sequences rather than verifying facts from trusted sources.
Limited Access to Private Information
Many organizations possess valuable internal knowledge that cannot be included during model training.
Examples include:
- Company policies
- Product specifications
- Internal process documents
- Customer records
- Compliance guidelines
Traditional models cannot access this information unless specifically integrated with external knowledge systems.
How Does a RAG System Work?
The RAG architecture introduces a retrieval step before response generation.
A simplified workflow is shown below.
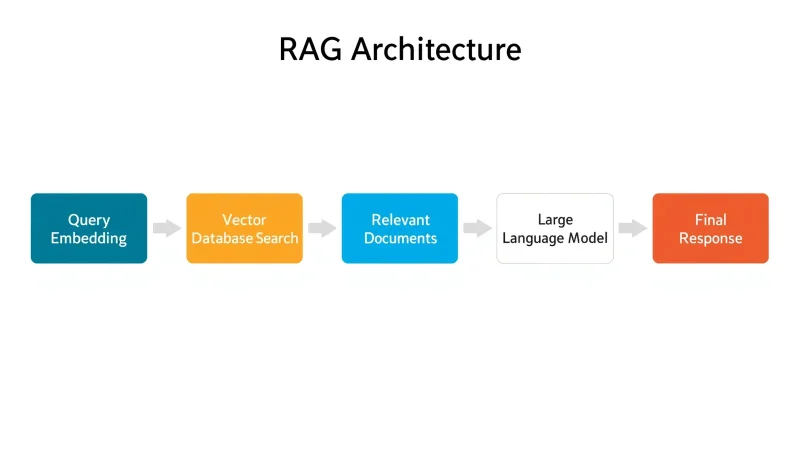 This workflow consists of multiple stages working together to produce accurate responses.
This workflow consists of multiple stages working together to produce accurate responses.
What Happens During the Retrieval Phase?
The retrieval phase is responsible for finding relevant information.
When a user submits a question, the query is converted into a numerical representation known as an embedding.
The system then compares this embedding against millions of stored document embeddings inside a vector database.
Rather than searching for exact keywords, the retrieval mechanism identifies documents with similar meaning.
For example, a user searching for:
"How can cloud applications be secured?"
may receive information related to:
- Identity management
- Encryption
- Network security
- Access control
- Zero trust architecture
even if those exact words were not present in the query.
This semantic search capability is one of the reasons RAG systems outperform traditional search methods.
What Are Embeddings and Why Are They Important?
Embeddings are numerical representations of text that capture meaning and relationships between words.
Every document, paragraph, or sentence can be transformed into a vector containing hundreds or thousands of numerical values.
Documents with similar meanings are positioned closer together in vector space.
This allows the system to identify relevant information based on context rather than exact keyword matches.
Embeddings form the foundation of modern AI retrieval systems and enable highly efficient semantic search capabilities.
What Role Do Vector Databases Play in RAG?
A vector database stores and retrieves embeddings efficiently.
Unlike traditional databases that rely on exact matches, vector databases focus on similarity search.
Popular vector database platforms include:
- Pinecone
- Weaviate
- Milvus
- Chroma
- Qdrant
These platforms can process millions of vectors and quickly identify the most relevant content for a given query.
Without vector databases, modern Retrieval Augmented Generation systems would struggle to scale effectively.
Why Is RAG More Reliable Than Traditional AI Models?
One of the biggest advantages of RAG is its ability to ground responses in actual information.
Instead of generating answers purely from learned patterns, the system references retrieved content before responding.
This provides several benefits:
Improved Accuracy
Responses are based on retrieved documents rather than assumptions.
Reduced Hallucinations
The model has access to supporting information, reducing the likelihood of fabricated answers.
Better Context Awareness
Responses can incorporate organization-specific knowledge.
Dynamic Information Access
New information can be added to the knowledge base without retraining the model.
Enhanced Trustworthiness
Users gain greater confidence when responses align with verified information sources.
What Are the Main Components of a Production RAG Architecture?
Enterprise-grade RAG systems typically contain multiple components.
Document Processing Layer
Responsible for:
- Data ingestion
- Content extraction
- Document cleaning
- Metadata generation
Chunking Layer
Large documents are divided into smaller sections to improve retrieval quality.
Embedding Model
Converts text into vector representations.
Vector Storage System
Stores embeddings for fast similarity searches.
Retrieval Engine
Identifies the most relevant content.
Large Language Model
Generates the final response using retrieved context.
Monitoring and Evaluation Layer
Tracks:
- Response quality
- Retrieval performance
- Latency
- User feedback
Together, these components create a robust AI solution capable of handling real-world business requirements.
Where Are RAG Systems Used Today?
RAG has become a core technology across multiple industries.
Enterprise Knowledge Assistants
Employees can query internal documentation using natural language.
Customer Support Platforms
AI assistants retrieve answers from product manuals and support articles.
Healthcare Systems
Medical professionals can access clinical references quickly.
Financial Services
Organizations can retrieve information from compliance and regulatory documents.
Software Development
Developers can search technical documentation, code repositories, and architecture guidelines more efficiently.
Research Applications
Researchers can retrieve relevant information from large collections of scientific literature.
These use cases demonstrate why RAG is becoming one of the most important AI architectures in enterprise environments.
What Challenges Exist When Building RAG Applications?
Although RAG offers significant benefits, implementation is not without challenges.
Poor Data Quality
Low-quality source documents lead to poor retrieval results.
Ineffective Chunking
Improper document segmentation can reduce search accuracy.
Retrieval Noise
Irrelevant documents may sometimes be returned.
Security Concerns
Sensitive information must be protected while still enabling retrieval.
Performance Overhead
Retrieval operations add additional processing steps that may increase response times.
Organizations must carefully design their architecture to balance accuracy, scalability, and performance.
Why Should Professionals Learn About RAG?
The rapid adoption of AI technologies is creating demand for professionals who understand modern AI architectures.
Knowledge of Retrieval Augmented Generation is becoming increasingly valuable for roles involving:
- Artificial Intelligence
- Machine Learning
- Data Engineering
- Cloud Computing
- Software Development
Many organizations involved in IT Hiring are actively seeking candidates who understand concepts such as embeddings, vector databases, semantic search, and Large Language Models.
For students and professionals focused on Upskilling, learning RAG provides practical exposure to technologies currently being implemented across industries.
These concepts are also becoming relevant during Interview Preparation for AI-related positions, as employers increasingly assess real-world understanding rather than purely theoretical knowledge.
As organizations adopt intelligent automation solutions, professionals who understand modern AI architectures improve their overall Job Readiness and long-term Career Growth prospects.
How Will RAG Shape the Future of Artificial Intelligence?
The future of AI is moving toward systems that combine reasoning with reliable access to information.
Emerging developments include:
- Agentic AI systems
- Multi-modal retrieval
- Real-time knowledge integration
- Enterprise AI assistants
- Autonomous business workflows
Rather than relying solely on memorized knowledge, future AI systems will increasingly retrieve, validate, and synthesize information dynamically.
RAG serves as a foundational building block for this next generation of intelligent applications.
Conclusion
Retrieval Augmented Generation represents a major advancement in how AI systems access and utilize information. By combining retrieval mechanisms with powerful language models, organizations can build solutions that are more accurate, reliable, scalable, and context-aware than traditional AI approaches. Understanding concepts such as embeddings, vector databases, semantic search, and retrieval pipelines helps professionals stay aligned with evolving industry requirements and modern technology trends.
For learners seeking practical exposure to emerging technologies, career-focused learning pathways, and structured technical development in Banashankari, Bangalore, institutions such as Scoop Labs are increasingly incorporating modern AI concepts into their learning ecosystem, helping students and professionals strengthen their technical expertise for the rapidly evolving digital landscape.
Submit a Request
Recent Posts




